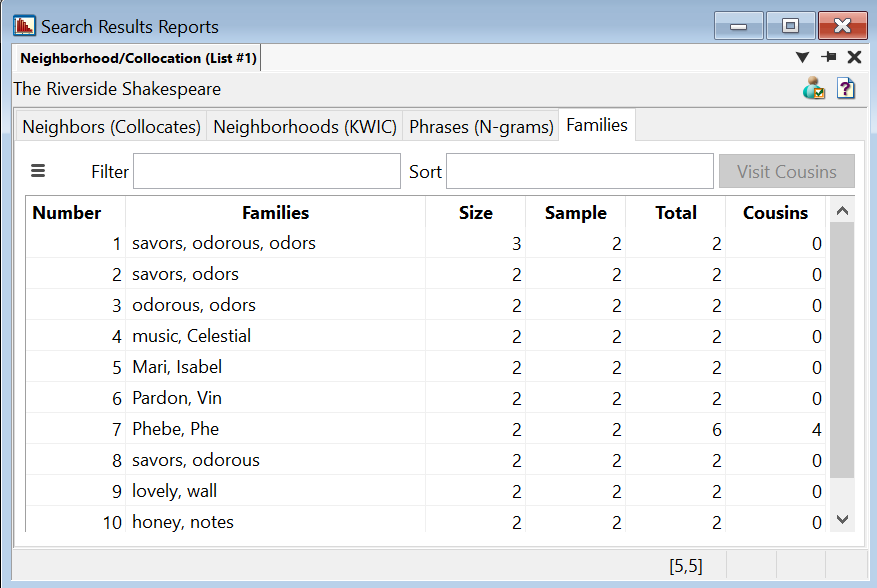
Tip: Double-click on a word to see it in context in the Neighborhoods (KWIC) tab.
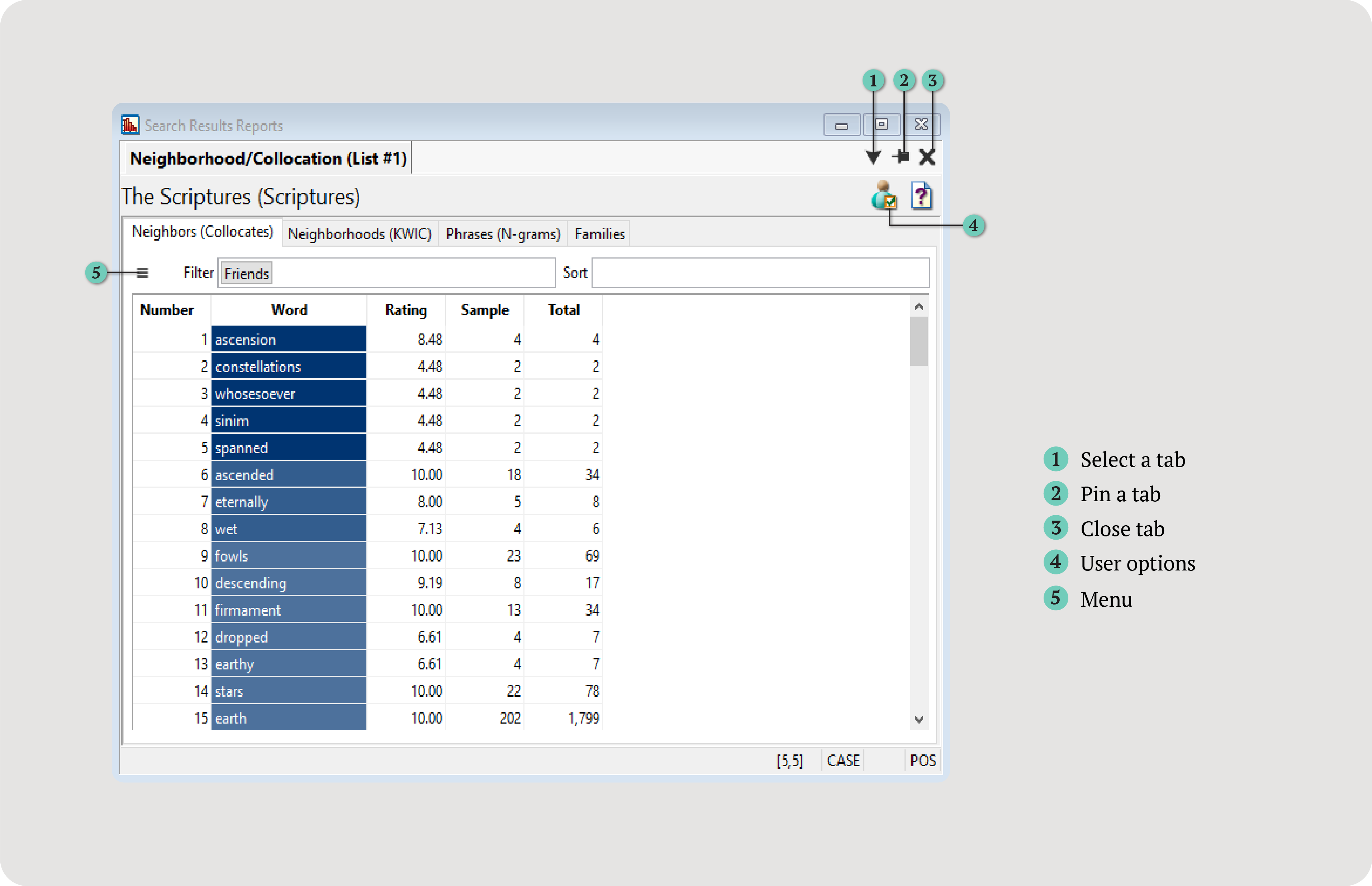
The Neighbors (Collocates) tab displays a list of all the words that occur near a search term. These words are the neighbors of the search words.
Words highlighted in blue are called friends (also known as collocates). Friends are words that significantly co-occur with the search term.
The darker the blue, the stronger the relationship between words. By default, friends are calculated within a range of five words before and
after the search term. To change these settings, click the Report Preferences button.
When you generate the report, you will see that the report is filtered by friends. To see all words that co-occur with the search term,
remove the filter.
A unique feature of WordCruncher’s Neighborhood Report (in comparison to other text analysis software) is that it accounts for word frequency.
Friends are ranked based on how often the friend appears near the search term, considering the number of times the friend also appears with other
words. Without considering this element, friends can tend to skew towards higher-frequency words.
Example:
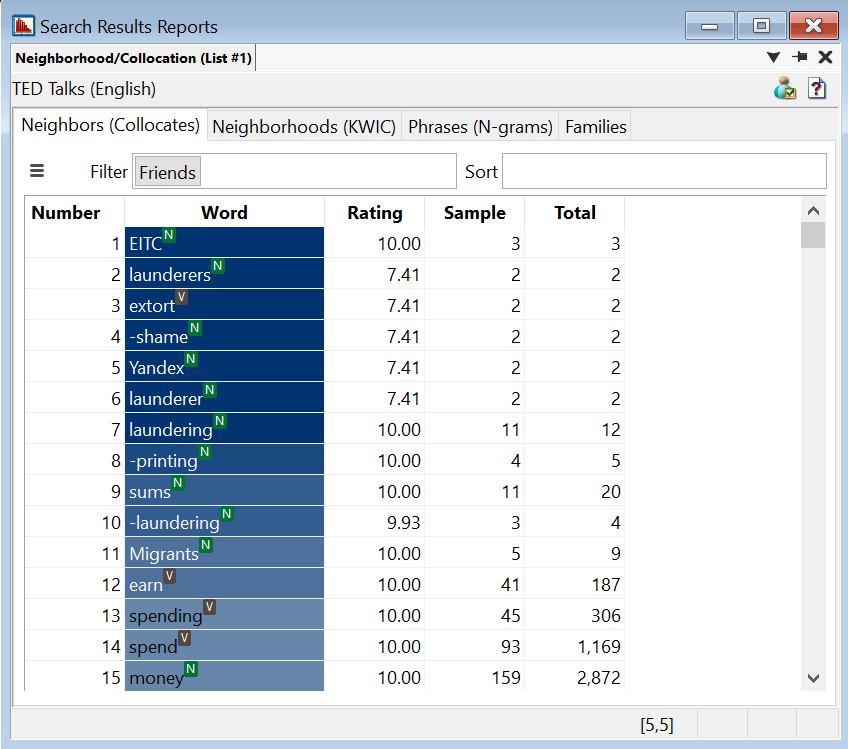
When you search for the word money in the TED Corpus (English), you’ll see that launderer (including launderers, laundering,
-laundering) is a strong friend, but it only appears a few times in the corpus. However, 18 out of 20 times that launderer appears, it co-occurs with money,
suggesting a very strong relationship.
Earn is another strong friend of money. Earn and money co-occur 41 times, which initially may appear to be a stronger relationship
than the one between launderer and money (which only co-occur 18 times). Earn, however, appears a total of 187 times in the text, so less than ¼ of its
occurrences actually co-occur with money. Because of this difference in frequency, launderer may have a stronger relationship with money than earn does,
although both are friends.
Columns
By default, the report will show the following columns. To show additional columns, use the hamburger menu.
- Number: The row number.
- Word: The neighbor. If this is a friend (collocate), it is highlighted in blue.
- Rating: A score between -10 and 10 (used to identify friends). To qualify as a friend, the rating must be greater than 0.
- Sample: The number of times the word co-occurs with the search term.
- Total: The total number of times the word occurs in the text.
For additional information on columns and statistics, view Neighbor or Collocate Statistics.